The Unfair Mutex
- by: Take Vos
- date: 15 Jun 2021
When working on HikoGUI system I needed a recursive mutex that is used often.
However std::recursive_mutex implementations can be extremely heavy, dwarfing
the amount of code it’s protecting.
In my quest to improve the performance of my own tt::unfair_recursive_mutex
I came to realize that in certain cases we can safely eliminate the need to
recursively lock, by using a feature of the tt::unfair_recursive_mutex
which is unavailable in std::recursive_mutex.
External locking
It is common for a thread-safe class to contain a mutex that is locked inside every member function of the class, when functions call other functions of the same object a recursive lock is needed. The idea of external-locking is instead to lock the mutex in the caller of the member function.
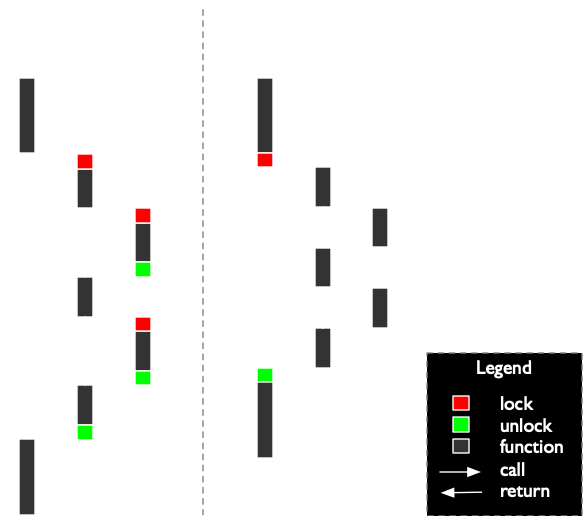
Of course it would be very easy to forget to lock before calling a function, this is where
the tt::unfair_recursive_mutex::recurse_lock_count() function comes in; this function
will return how many times the lock has been taken by the current thread, otherwise zero.
By adding an assert(recurse_lock_count() > 0) in
each member function we can make sure that the member function will be called with the
lock held by the current thread.
The assert above is not subject to race conditions, this means we can eliminate the check in release builds, as long as unit/module/system-tests will exercise every call to the assert-protected-function at least once.
But the recurse_lock_count() function is also very fast, faster than taking a recursive
lock, so a check in release builds may be a good idea in certain cases.
In HikoGUI a global gui_system_mutex is used by widgets, windows, devices, graphic-pipelines,
draw-context and more. Many of the functions in the GUI system only assert on the
recurse_lock_count() in expectation that most calls are recursive from somewhere else
in the GUI system. A mixture of some functions asserting and other functions recursively
locking is completely supported.
The rest of the article goes deeper into the implementation of the unfair_mutex and
unfair_recursive_mutex.
tt::unfair_mutex
The normal std::mutex is “fair” meaning that if there are multiple threads contending for a lock on the mutex, it will fairly determine which thread will wake up and acquire the lock.
The tt::unfair_mutex does none of this, in fact it may be possible for threads
waiting on a lock to never get woken up, in effect the thread is being starved.
Therefor the tt::unfair_mutex should only be used when it is rare for two
threads to contend for a lock.
The tt::unfair_mutex is a straightforward implementation from the paper
“Futexes Are Tricky” by Ulrich Drepper.
Below I have included some excerpt of the lock() implementation.
Here you can see that I use the new c++20 std::atomic::wait() and std::atomic::notify_one()
which exposes a limited but generic variant of the futex.
void unfair_mutex::lock() noexcept
{
uint32_t expected = 0;
if (!state.compare_exchange_strong(expected, 1, memory_order::acquire)) {
[[unlikely]] lock_contended(expected);
}
}
At the call site of unfair_mutex::lock() the following assembly is generated by MSVC:
; Retrieve the this pointer for the mutex.
00007FF77369C016 lea rcx,[mutex (07FF773B7A800h)]
; Unoptimized dead-store.
00007FF77369C01D mov qword ptr [rsp+30h],rcx
; The next three instructions are the compare_exchange_strong(eax, 1).
00007FF77369C022 mov edx,1
00007FF77369C027 xor eax,eax
00007FF77369C029 lock cmpxchg dword ptr [mutex (07FF773B7A800h)],edx
; The if statement, with a forward jump beyond the end of the function
; containing a call to lock_contended().
00007FF77369C031 jne foobar+0C7h (07FF77369C0B7h)
To reduce the code size at the call site of lock(), which is expected to be inlined,
I split up the lock function in a non-contended and contended part and direct
the compiler to never inline the lock_contended() function.
I also use [[likely]] and [[unlikely]] to suggest to the compiler the preferred,
non-contended, code-path.
As you can see from the generated assembly this resulted in a forward conditional jump
for the contended path, on x86-64 forward jumps are initially predicted to not be taken.
And the call site of the lock_contended() is beyond the current function’s code which
will reduce instruction cache usage.
tt::unfair_recursive_mutex
The tt::unfair_recursive_mutex is also a straightforward implementation.
It uses the tt::unfair_mutex and the member variables owner (the owning thread id)
and count (recurse count).
void unfair_recursive_mutex::lock() noexcept {
auto const thread_id = current_thread_id();
if (owner.load(memory_order::acquire) == thread_id) {
++count;
} else {
mutex.lock();
count = 1;
owner.store(thread_id, memory_order::release);
}
}
MSVC generates the following assembly at the call site of
unfair_recursive_mutex::lock():
; Unoptimized dead-load and dead-store.
00007FF7DC552459 lea r14,[mutex (07FF7DCA46AA0h)]
00007FF7DC552460 mov qword ptr [rsp+60h],r14
; A single instruction current_thread_id().
00007FF7DC552465 mov edi,dword ptr gs:[48h]
; Get the unfair_recursive_mutex::owner variable.
00007FF7DC55246D mov eax,dword ptr [mutex+4h (07FF7DCA46AA4h)]
00007FF7DC552473 nop
; Check if the current thread id is the (previous owner) of the lock.
00007FF7DC552474 cmp eax,edi
00007FF7DC552476 jne foobar+50h (07FF7DC552480h)
; This was the owner; increment unfair_recursive_mutex::count.
00007FF7DC552478 inc dword ptr [mutex+8h (07FF7DCA46AA8h)]
; Continue with the function.
00007FF7DC55247E jmp foobar+72h (07FF7DC5524A2h)
; Try to non-contended lock of the unfair_mutex.
00007FF7DC552480 mov ebp,1
00007FF7DC552485 xor eax,eax
00007FF7DC552487 lock cmpxchg dword ptr [mutex (07FF7DCA46AA0h)],ebp
; Forward jump to unfair_mutex::contended_lock().
00007FF7DC55248F jne foobar+1A0h (07FF7DC5525D0h)
; Set the unfair_recursive_mutex::count to 1.
00007FF7DC552495 mov dword ptr [mutex+8h (07FF7DCA46AA8h)],ebp
00007FF7DC55249B nop
; Set the unfair_recursive_mutex::owner to the current_thread_id().
00007FF7DC55249C mov dword ptr [mutex+4h (07FF7DCA46AA4h)],edi
; Continue with the rest of the function.
00007FF7DC5524A2
For performance reasons we need to retrieve the thread id quickly.
On Windows we can retrieve the thread id from the Thread Information Block.
We can use the following intrinsic __readgsdword(0x48) to get the thread id in a single instruction.
On other platforms there are similar solutions to the thread information block.
As a fallback we can use the address of a thread_local variable as a thread-id,
since we only need a unique thread id, not the actual operating systems’ thread id.